Ambient Diffusion: Reducing Dataset Memorization by Training with Heavily Corrupted Data

DALL-E, Midjourney and Stable Diffusion are powerful text-to-image diffusion generative models that can turn arbitrary user prompts into highly realistic images. These models are trained on billions of image-text pairs, and they can generate high-quality images from textual descriptions. However, the dataset used to train these models is not publicly available and potentially contains copyrighted images. Despite the sheer size of their training set, diffusion models are known ([1], [2]) to memorize seen examples and replicate them in generated samples. This has led to a series of lawsuits against the major AI research labs that developed these models ([3], [4], [5]).
To reduce the memorization of the training set, researchers at UT Austin in collaboration with UC Berkeley developed the first framework to train diffusion models with only access to corrupted training data. The proposed Ambient Diffusion framework can be used to generate high-quality samples without ever seeing an uncorrupted image.

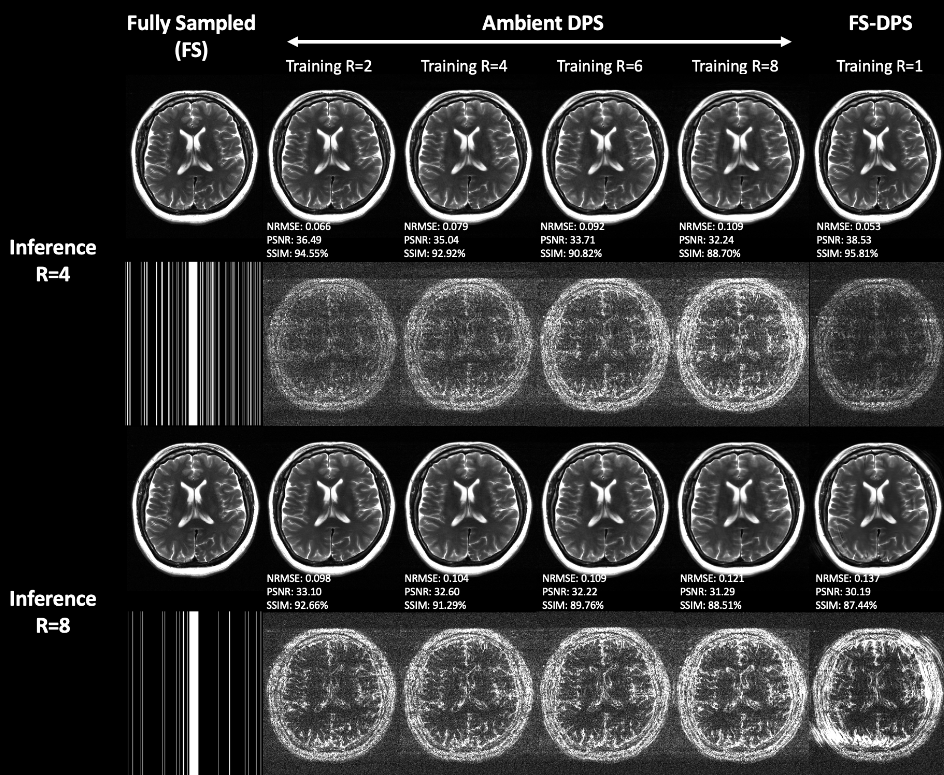
Ambient Diffusion can be also used in scientific applications where it is expensive or impossible to acquire fully observed or uncorrupted data, such as black hole imaging or MRI acceleration. The work is led by the 4th year Computer Science Ph.D. student Giannis Daras under the supervision of the directors of the Institue of Foundations of Machine Learning (IFML), Alexandros G. Dimakis and Adam Klivans.
As their first experiment, the team trained a diffusion model on a set of 3000 images of celebrities. Then, they used the model to generate new samples and compared the generated samples to their nearest neighbor in the dataset.

The diffusion model trained on clean data blatantly copied the training examples. The team proceeded to corrupt the training data by randomly masking individual pixels and retrained the diffusion model using the Ambient Diffusion framework. The generated samples from the ambient model were found to be sufficiently different from the training examples, as shown in the figure above.
This memorization behavior is not limited to models trained on small datasets. The team demonstrated that state-of-the-art diffusion models, such as Stable Diffusion XL (SDXL), also memorize their training data. They did this using a two step process: (1) mask significant parts of images that are suspected to be in the training set and then (2) use the model as a prior to reconstruct the missing pixels. The reconstructed images are almost identical to the original images, which indicates that the model has memorized them (see Figure 1).
The team further showed that the SDXL model can also perfectly reconstruct images that are severely corrupted with additive Gaussian noise. 
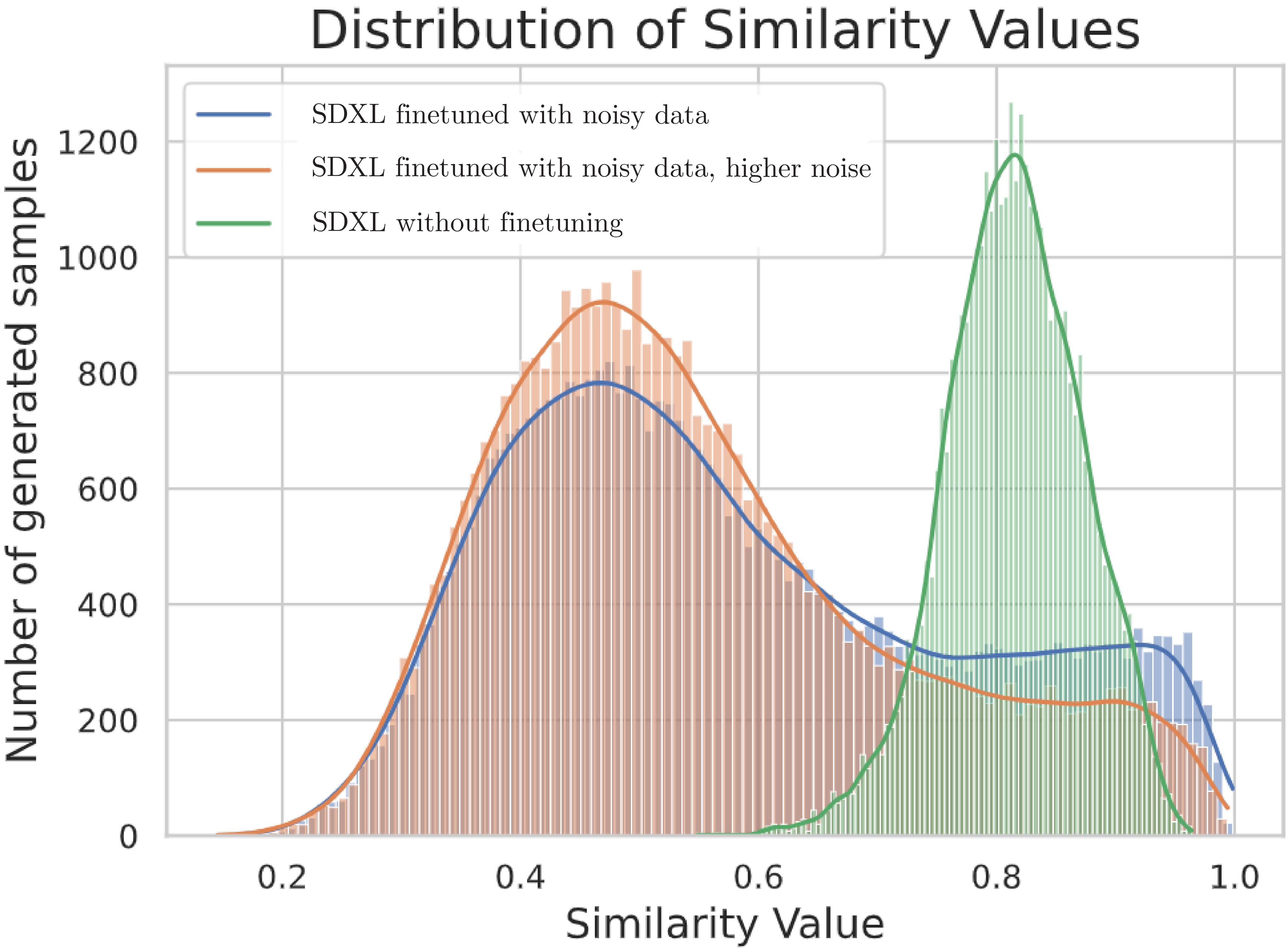
In collaboration with MIT Professor Constantinos Daskalakis, the Ambient Diffusion framework was extended to train diffusion models on datasets of images corrupted by other types of noise, rather than by simply masking pixels. The new work, called Consistent Diffusion Meets Tweedie, can be used to finetune Stable Diffusion XL on data with additive Gaussian noise and significantly reduce the memorization of the training set.
The theory behind the paper predicts that we can train diffusion models that sample from the distribution of interest for any level of corruption. This solves an open-problem in the space of training generative models with corrupted data.
The finetuned SDXL Ambient Diffusion models can generate high-quality samples for arbitrary user prompts.

In practice, performance may degrade for extremely high corruption levels. Yet, the models will never output noisy images.

 *
*The Ambient Diffusion framework allows to control the trade-off between memorization and performance: as the level of corruption encountered during training increases, the memorization of the training set decreases at the potential cost of performance degradation.
 *
*The original Ambient Diffusion work has been presented in the top-tier machine learning conference NeurIPS 2023. The code for both papers is available on Github ([6], [7]).
Going forward, the team plans to apply the Ambient Diffusion framework to scientific applications where access to clean data is expensive or impossible. The work has already been applied to train diffusion models for MRI acceleration and has shown promising results. The Ambient Diffusion framework has the potential to lead to improved datasets in various scientific domains by removing the inherent noise that is present in the training samples.